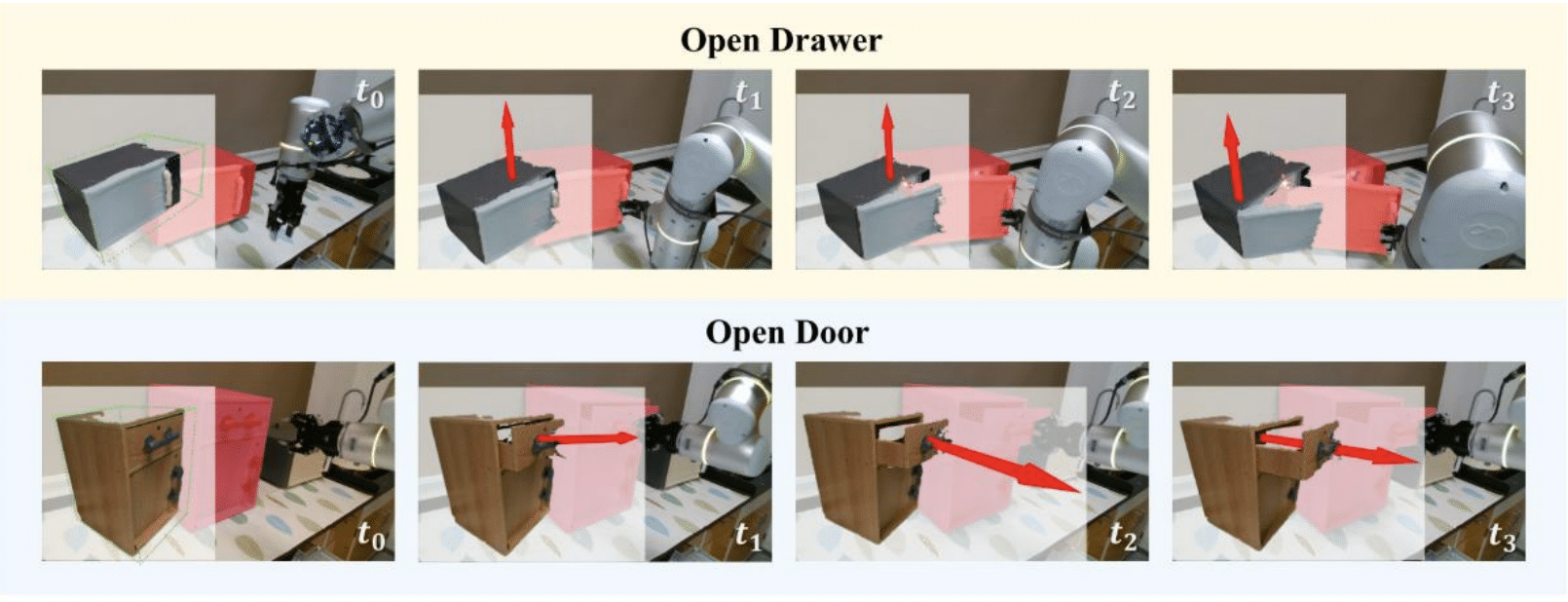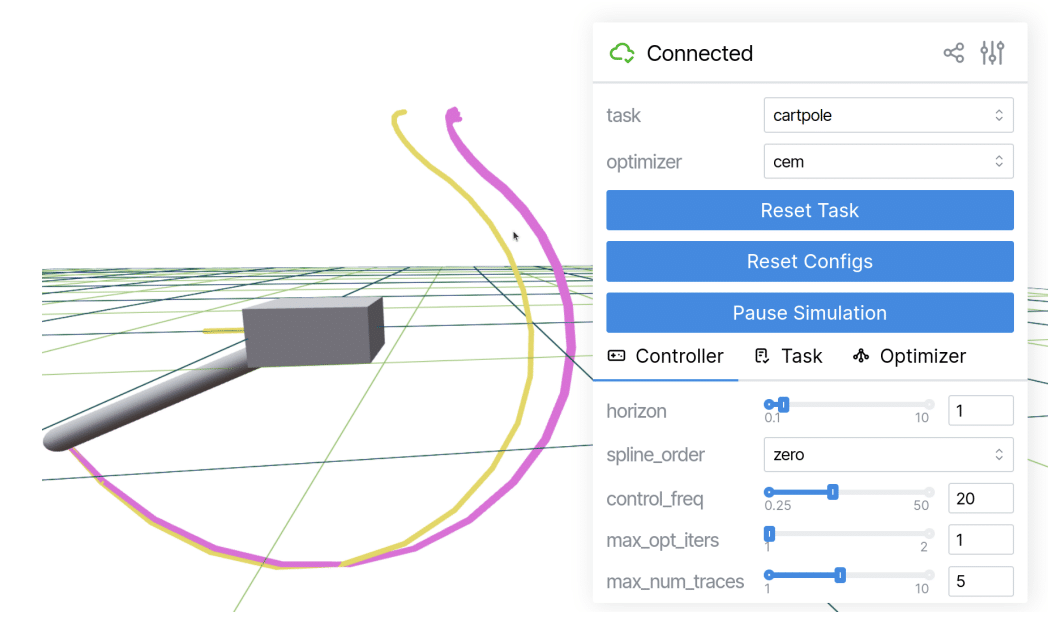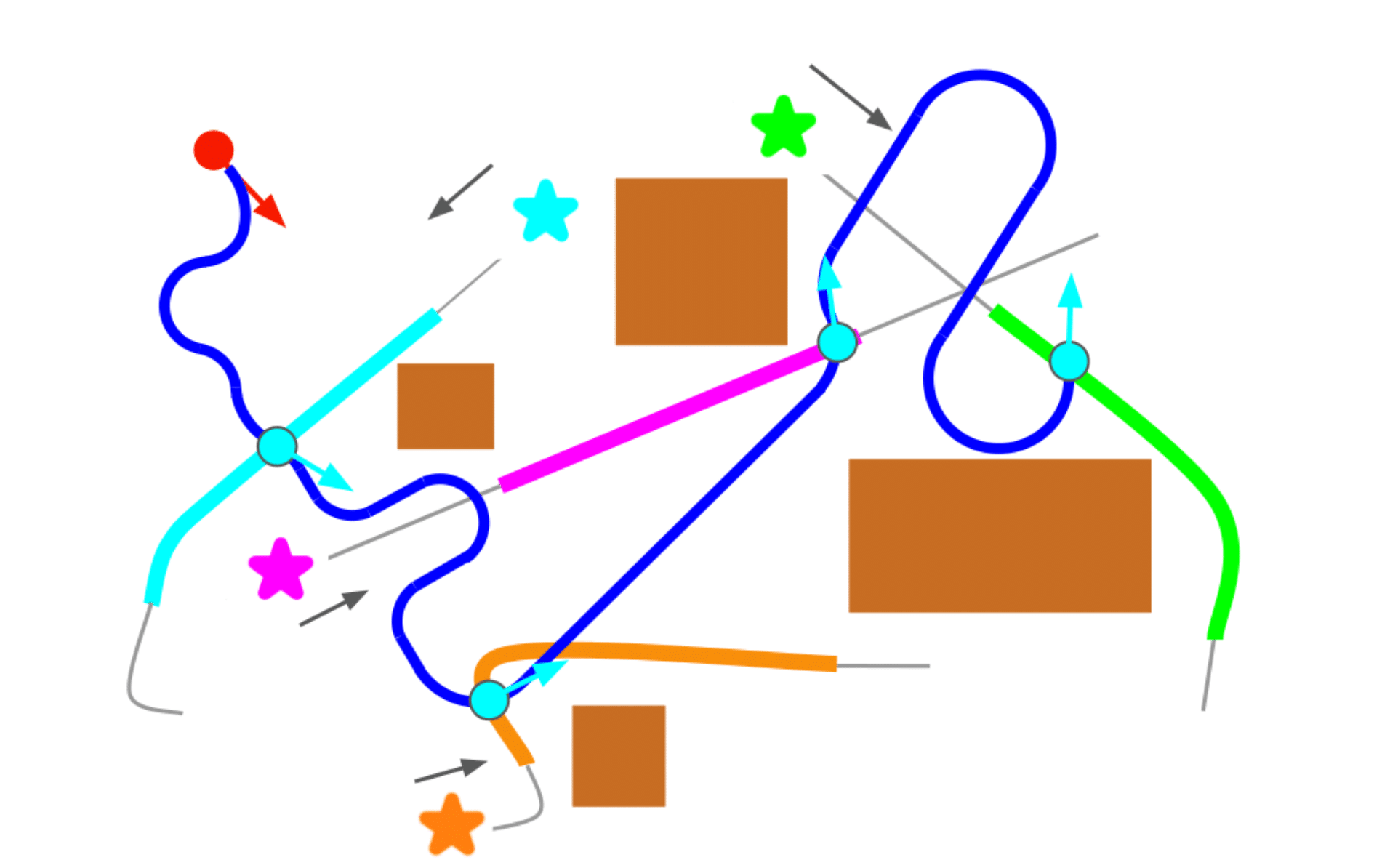

We examine the motivations behind building documentation tools, how authors conceptualize documentation practices, and how these tools connect to existing systems, regulations, and cultural norms.
Flip Stunts on Bicycle Robots using Iterative Motion Imitation
This work demonstrates a front-flip on bicycle robots via reinforcement learning, particularly by imitating reference motions that are infeasible and imperfect. To address this, we...