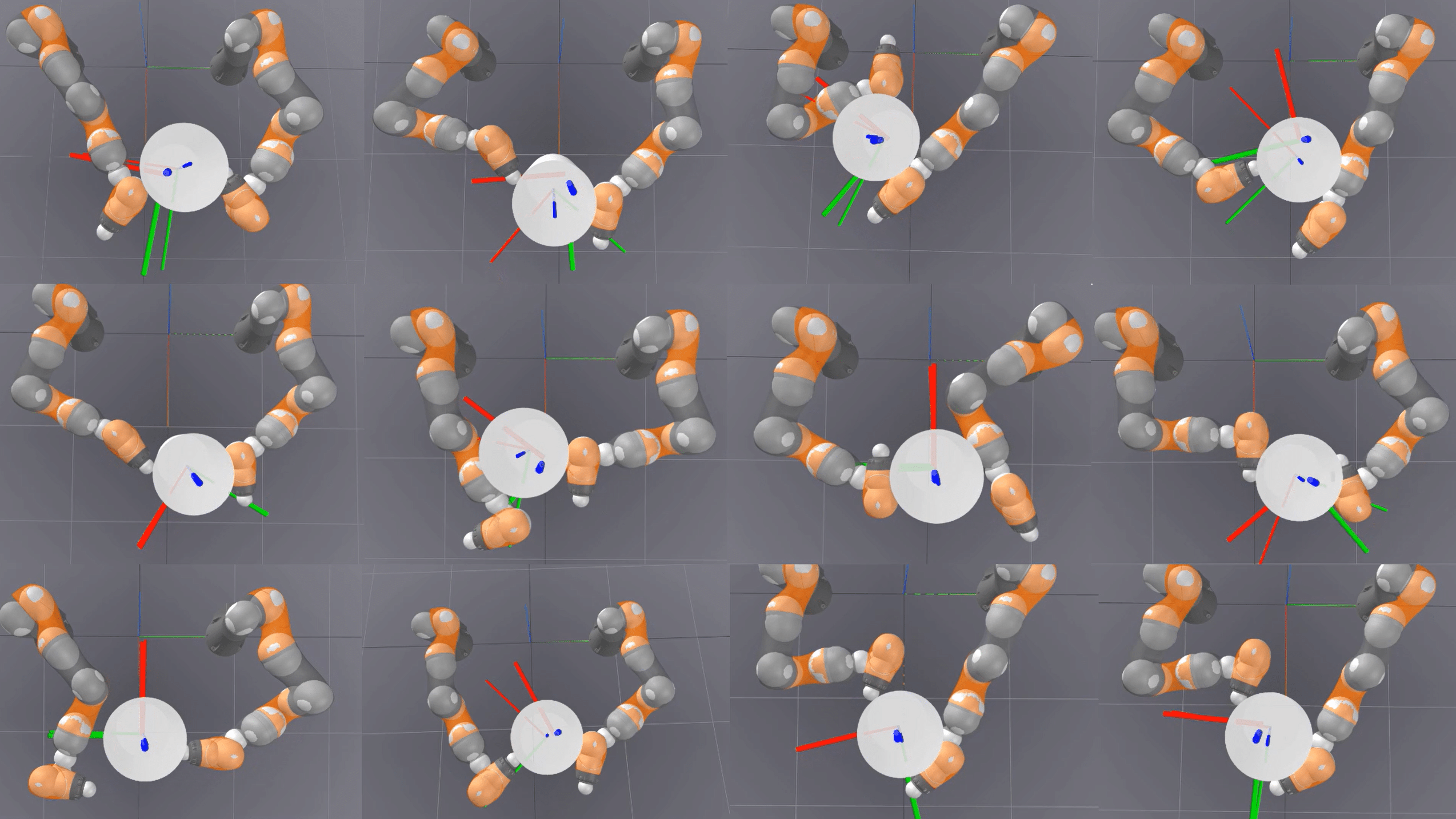
Researchers present Diffuse-CLoC, a guided diffusion framework for physics-based look-ahead control that enables intuitive, steerable, and physically realistic motion generation.
We’ve opened a free, hands-on robot lab for the summer! Plan your visit.