
In This Story
Force Admittance Control of an Underactuated Gripper with Full-State Feedback
Chunpeng Wang, David Nguyen, Zhi Ern Teoh, Ciaran O’Neill, Lael Odhner, Peter Whitney, Matthew A. Estrada
To move closer to the goal of next-generation hardware design capable of more human-like manipulation, researchers at the RAI Institute have developed a new type of robotic gripper driven by compressed air pressure via a pneumatic rolling diaphragm actuator. The gripper utilizes its joint encoders to understand contact force, allowing it to adjust its grip strength automatically without additional tactile sensors or cameras.
Testing has shown that this gripper can accurately control its grip strength and perform basic grasping tasks, such as finding and picking up objects, and even detecting when an object slips from its grasp. These results suggest that this approach could lead to the development of lightweight, adaptable robotic grippers that are sensitive enough to react to contact events without distal sensors or vision.

High-Performance Reinforcement Learning on Spot: Optimizing Simulation Parameters with Distributional Measures
A.J. Miller, Fangzhou Yu, Michael Brauckmann, Farbod Farshidian
This work presents an overview of the technical details behind a high-performance reinforcement learning policy deployment with the Spot RL Researcher Development Kit for low-level motor access on Boston Dynamics’ Spot. This represents the first public demonstration of an end-to-end reinforcement learning policy deployed on Spot hardware with training code publicly available through NVIDIA IsaacLab and deployment code available through Boston Dynamics.
To measure the gap between simulated and real-world data, researchers used Wasserstein Distance and Maximum Mean Discrepancy to quantify the distributional dissimilarity of data collected on hardware and in simulation. These measurements were then used as a scoring function for the Covariance Matrix Adaptation Evolution Strategy to fine-tune the simulated model parameters of this particular Spot model. This process of modeling and training resulted in high-quality reinforcement learning policies that enabled Spot to perform various gaits, including ones that involve a flight phase. These policies allowed Spot to achieve locomotion speeds exceeding 5.2 m/s, which is more than three times its default maximum speed. Additionally, Spot demonstrated robustness against slippery surfaces and external disturbances not previously observed.
A detailed explanation of the method and release of the code has also been provided to encourage further research using Spot’s low-level API.
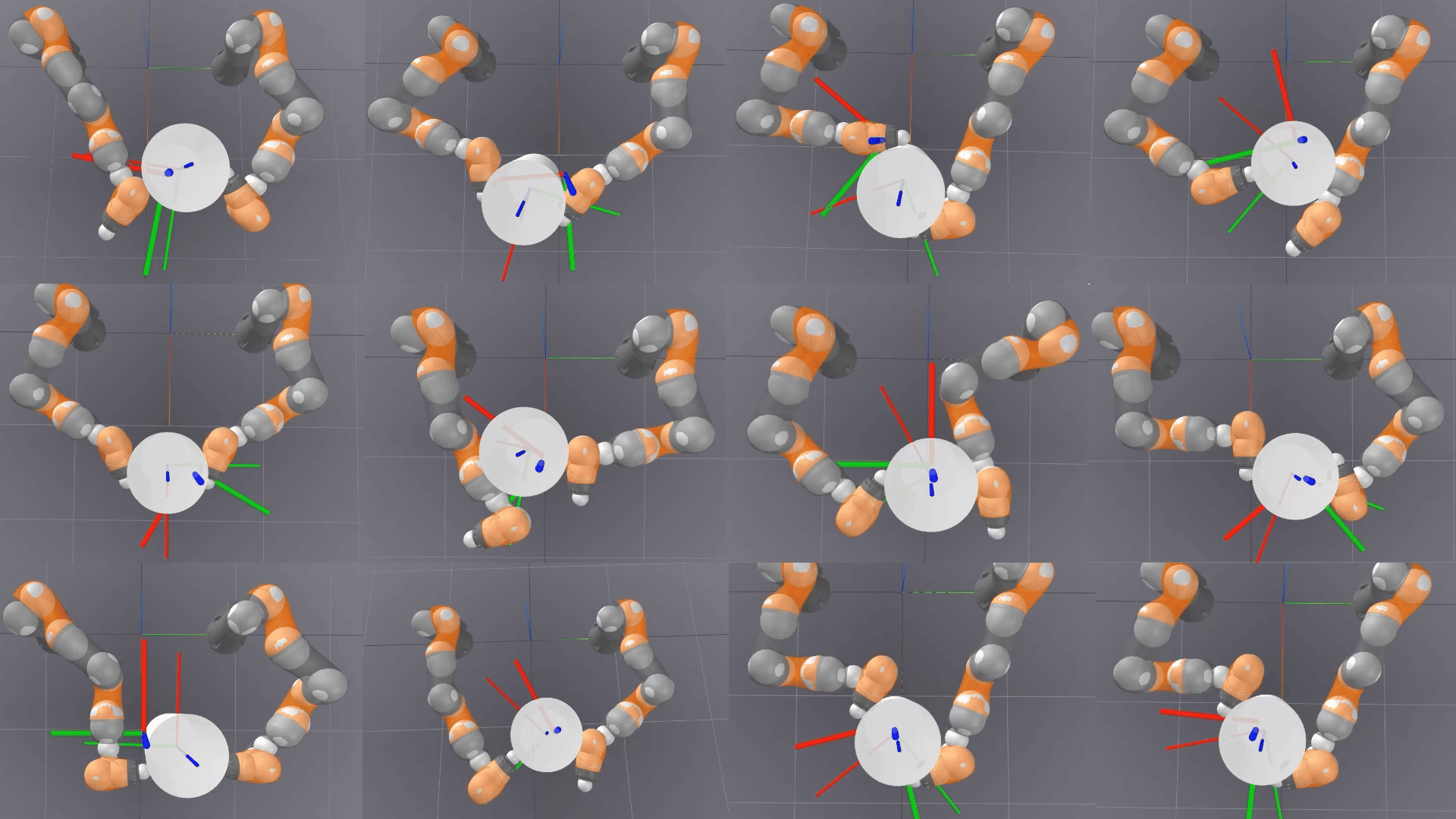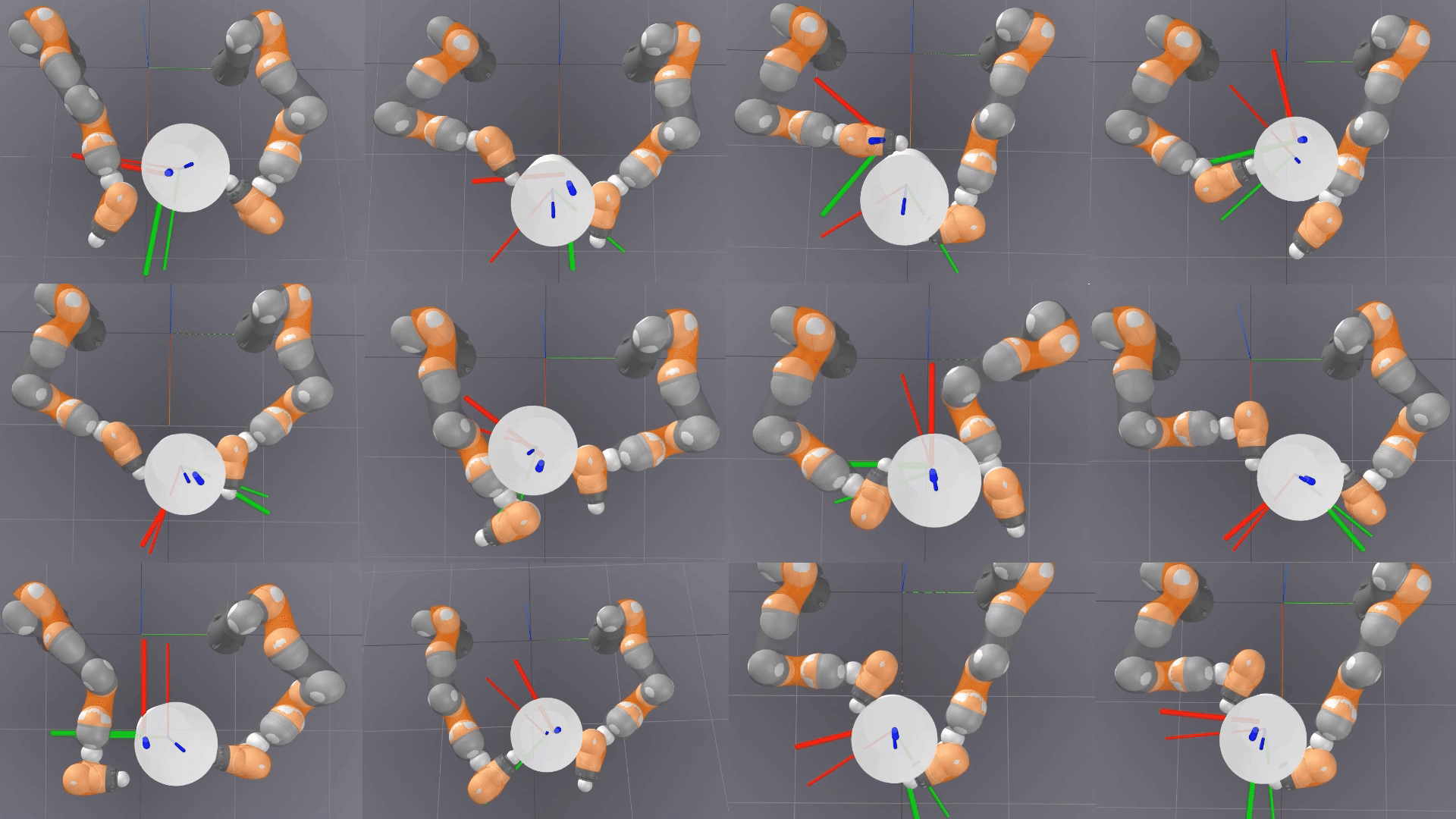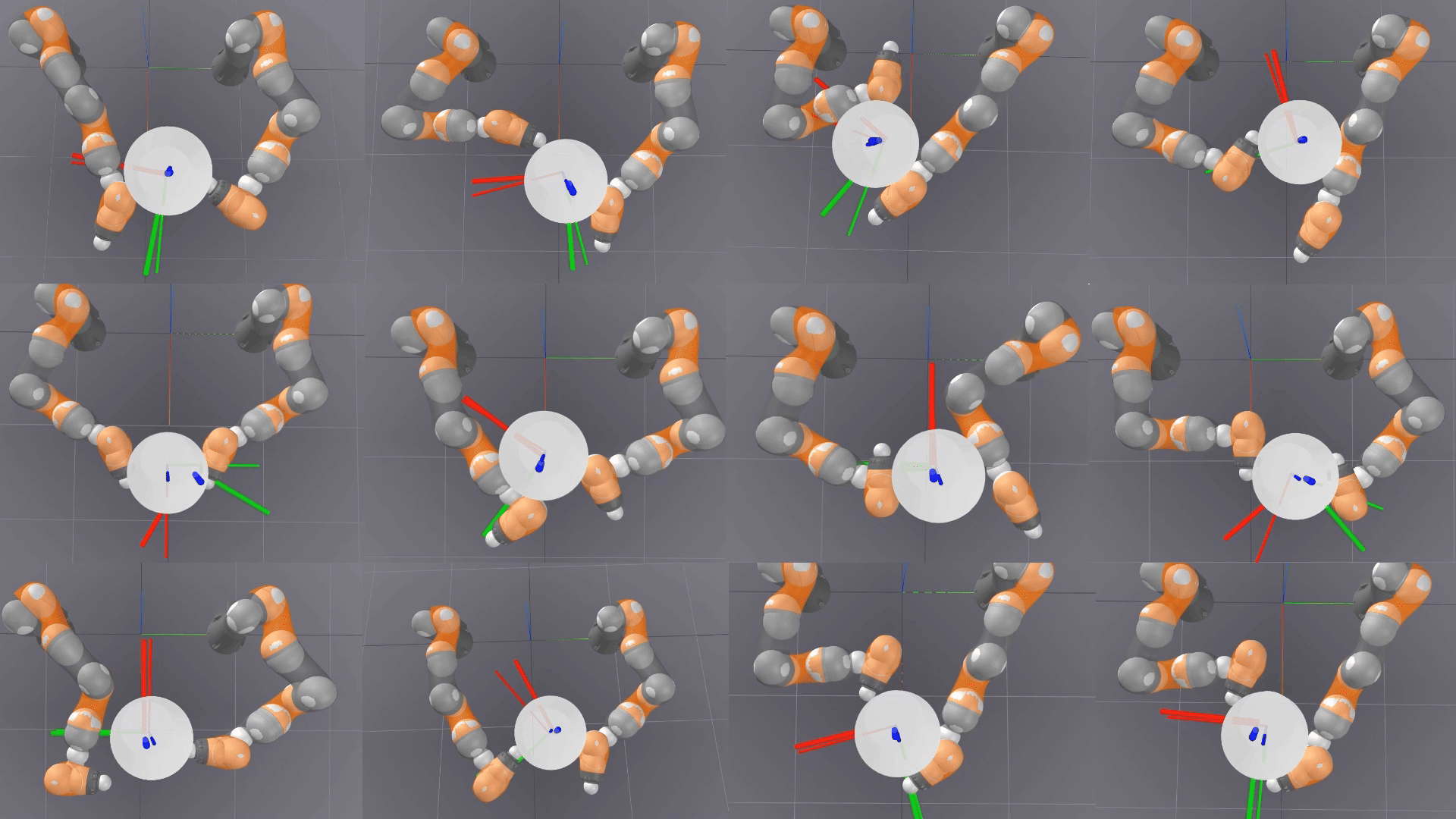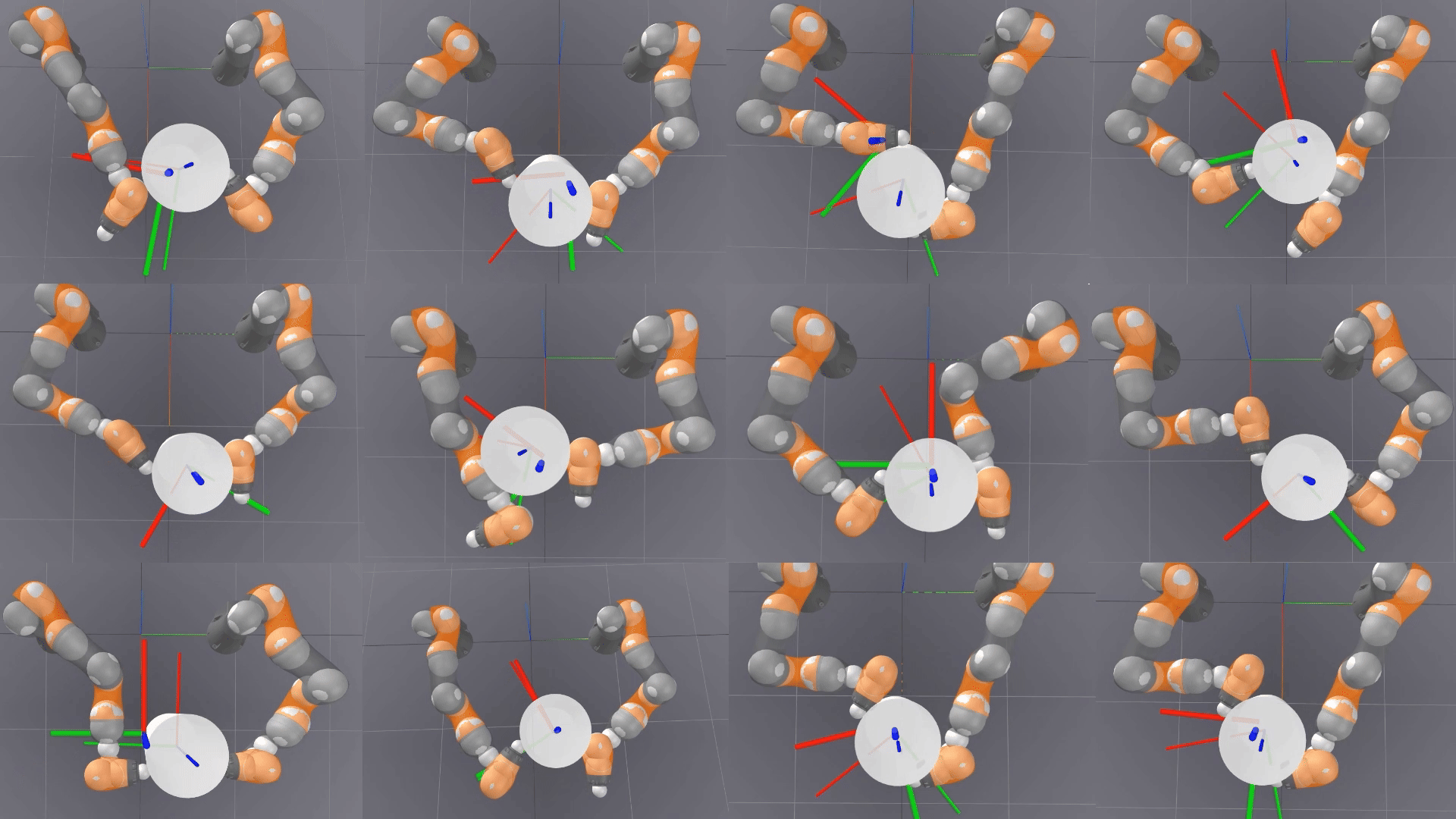
Is Linear Feedback on Smoothed Dynamics Sufficient for Stabilizing Contact-Rich Plans?
Yuki Shirai, Tong Zhao, H.J. Terry Suh, Huaijiang Zhu, Xinpei Ni, Jiuguang Wang, Max Simchowitz, Tao Pang
Designing planners and controllers for robots to manipulate objects in contact-rich situations is difficult because contact creates unexpected abrupt changes that many computer-aided design tools for robot control don’t account for. Contact smoothing can help by approximating abrupt changes with smoother transitions, making it easier to use design tools. However, although contact smoothing techniques have been investigated for planners, it is not clear how these techniques are useful for designing feedback controllers for contact-rich manipulation.
Researchers at the RAI Institute examine the effectiveness of linear feedback controllers for contact-rich robotic manipulation, with differentiable simulations that use contact smoothing.
This research introduces fundamental methods for using contact smoothing and robust optimization to create robot plans that are resistant to uncertainties and errors, and to maintain stability during these plans. The research used a bimanual whole-body manipulation as a testbed for these methods for over 300 trajectories to determine why a common control method, linear quadratic regulator (LQR), isn’t enough for maintaining stability in plans with a lot of contact.

On-Robot Reinforcement Learning with Goal-Contrastive Rewards
Ondrej Biza, Thomas Weng, Lingfeng Sun, Karl Schmeckpeper, Tarik Kelestemur, Yecheng Jason Ma, Robert Platt, Jan-Willem van de Meent, Lawson L. S. Wong
Reinforcement Learning (RL) has the potential to enable robots to learn from their own actions in the real world. Unfortunately, RL can be prohibitively expensive, in terms of on-robot runtime, due to inefficient exploration when learning from a sparse reward signal. Additionally, designing comprehensive reward systems is time-consuming and demands extensive domain knowledge.
To account for this, researchers at the RAI Institute propose GCR (Goal-Contrastive Rewards), a dense reward function learning method that can be trained on passive video demonstrations. By using videos without actions, the method is easier to scale, as arbitrary videos can be used. GCR combines:
- Two loss functions
- An implicit value loss function that models how the reward increases when traversing a successful trajectory
- A goal-contrastive loss that discriminates between successful and failed trajectories.
Researchers performed experiments in simulated manipulation environments across RoboMimic and MimicGen tasks, as well as in the real world using a Franka arm and a Spot quadruped. Research has found that GCR leads to a more-sample efficient RL, enabling model-free RL to solve about twice as many tasks as their baseline reward learning methods. Researchers also demonstrate positive cross-embodiment transfer from videos of people and of other robots performing a task.

